Agents write the code.The job is everything else.
Reviews, deploys, debugging, audits, on-call. clu is the context layer agents need to handle that work without turning into chaos.
agents need to know:
- Which repo deploys where?
- Which service serves which customer?
- Which incident woke up which on-call?
That's the map clu builds.
Code review is the wedge.
We start with code review because source code is the highest signal feed for the graph.
A reviewer handed an agent-produced diff sees the output and none of the work. They can't tell what the agent tried, where it pushed back, or where it confidently went the wrong direction. Reviews get less rigorous than they were before AI was in the loop, exactly when the stakes are higher.
clu packages the agent thread alongside the diff. The conversation that produced the change sits next to the code that came out of it. Comments thread on either side.
The diff is a verification artifact. The thing being reviewed is the reasoning. Every review feeds the graph beneath.
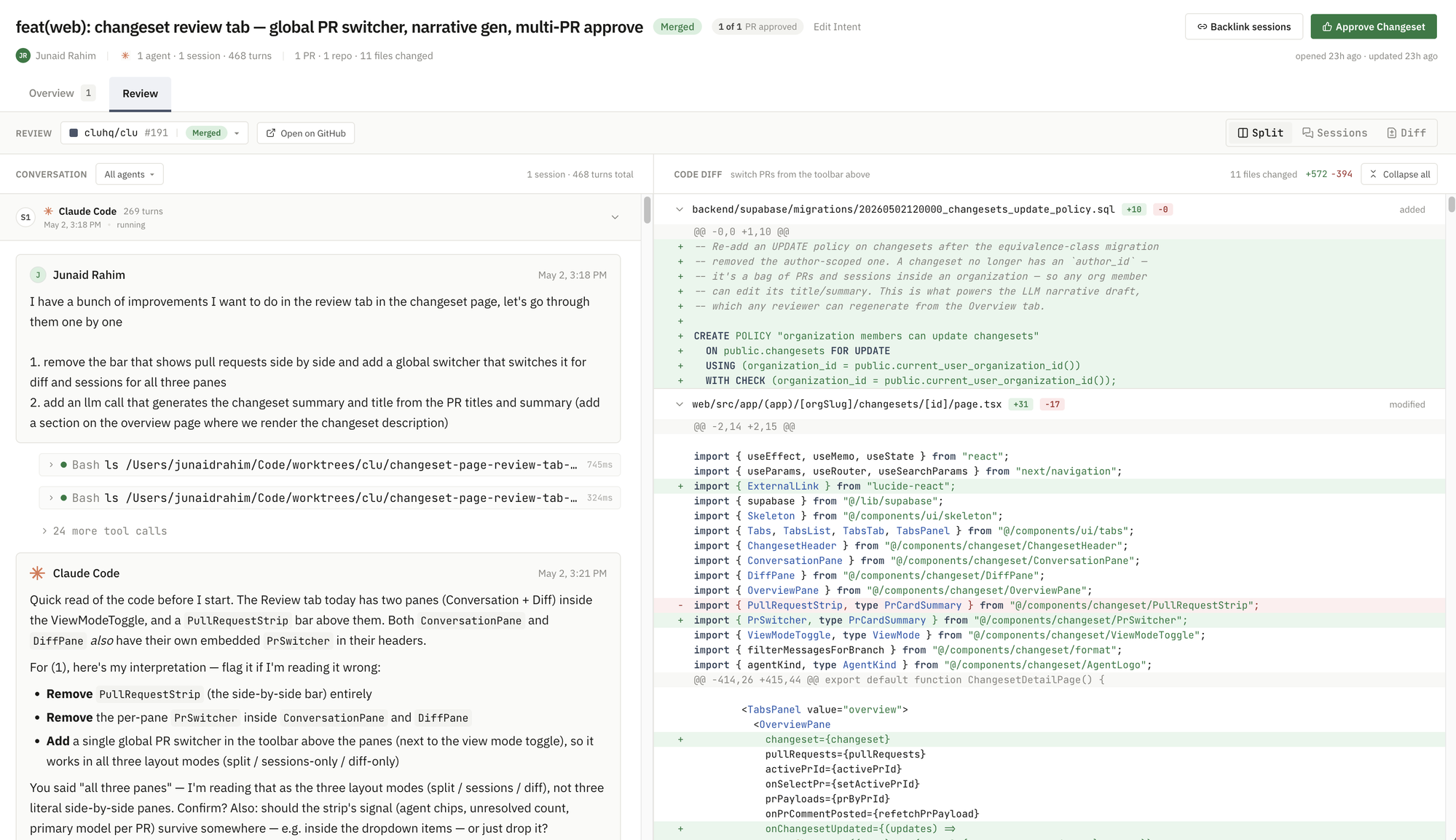
One change, many repos.
Real work doesn't respect repo boundaries. An agent session that adds a feature often touches a backend repo and a frontend repo in lockstep. Two PRs today means two disconnected reviews and a lost end-to-end story.
A clu changeset bundles them together. One review for one change, no matter how many repos it touched.
Add usage tier to billing
Backend schema adds a tier enum and migrates existing rows to standard. Frontend types and the billing dashboard pick up the new field.
The graph beneath the code.
Underneath every review is a relationship. A repo deploys to a cluster, a cluster serves a customer, a customer pays a bill. Today that map lives in tribal knowledge: a senior engineer's head, a stale Notion page, the comms history of a Slack channel.
clu makes it explicit. An opinionated ontology defines the types; the graph holds the actual ids and bodies. Lock down what a repo, a deployment, a customer mean for your org once, and every agent that follows queries against the same shape.
- reponode 01
cluhq/api
main · 1,284 commits
- deploys-todeploymentnode 02
eks/prod-cluster
us-east-1 · 12 services
- servescustomernode 03
cus_182
acme corp · since 2024
- generatesrevenuenode 04
stripe/sub_K12
$480k ARR · enterprise
Types are defined by the org's ontology. The graph holds the actual ids and bodies. Any agent, yours or ours, queries against the same shape.
Connectors do the listening.
A graph is only as true as the moment it was last touched. Without it, every agent re-discovers the org on every prompt. clu subscribes to the systems of record engineers already use, webhooks, event streams, periodic pulls, and proposes graph updates as reality shifts.
High-confidence updates auto-merge. Ambiguous ones queue for a human. Every change carries a decision trace, so when an agent acts on context later, you can audit the chain that got it there.
- sourcegithub · gitlab · bitbucket
- issueslinear · jira · github issues
- ci/cdgithub actions · circleci · buildkite
- cloudaws · gcp · azure
- runtimekubernetes · ecs · nomad
- observabilitydatadog · grafana · sentry
- incidentspagerduty · incident.io · opsgenie
- commsslack · discord · teams
- customersstripe · salesforce · intercom
Connectors propose graph updates as events arrive. High-confidence updates auto-merge. Ambiguous ones queue for a human.
- · 3,418 nodes
- · 12,907 edges
- · 2 updates pending review
Every change carries a decision trace. When an agent acts on context, you can see why.
The layer underneath.
clu exposes the graph through idiomatic APIs and MCP. Hook it into Claude Code, Codex, Cursor, your own harness, or whatever lands next month.
Most tools hoard context. They lock teams into one harness, one agent, one UI. The model and harness landscape is moving too fast for that bet to make sense. Pick whatever fits the job. clu comes with you.
{
"tool": "clu_query_context",
"args": {
"subject": "cluhq/api",
"depth": 2,
"include": ["deployment", "customer"]
}
}from clu import graph
ctx = graph.ask(
subject="cluhq/api",
depth=2,
include=("deployment", "customer"),
)Same context, same call, whichever harness or model is on the other end. Pick what fits the job. clu travels with you.
Out of the way until you need it.
clu's CLI installs hooks into your coding agent and then gets out of the way. No daemon. Every command is idempotent. Errors are recoverable by retrying.
You push code the way you already do. clu correlates the agent session to the PR and assembles the changeset. The review surface is there when you need to look at something, not asking for attention when you don't.
What clu is not.
- Not a VCS.You keep pushing to GitHub.
- Not a coding agent.You keep using Claude Code, Codex, whatever comes next.
- Not a CI system.clu does not run your tests or gate your merges.
- Not a project management tool.clu links to your tickets. It doesn't replace your tracker.
- Not another dashboard.We extract the relationships your tools encode, we don't replace them.